 Today, log files are everywhere! Each server or network component generates tons of log entries. All of them are interconnected to build complex infrastructures. Log files are often the first and only way to detect unusual events. The problem of security people is to be able the extract the right information at the right time. Browsing logs is definitively boring, time and money consuming and, helas, not performant enough (no correlation). Depending on your infrastructure, your devices can generate up to GigaBytes of log entries per day. It becomes impossible to review them manually. You need tools to achieve this.
Today, log files are everywhere! Each server or network component generates tons of log entries. All of them are interconnected to build complex infrastructures. Log files are often the first and only way to detect unusual events. The problem of security people is to be able the extract the right information at the right time. Browsing logs is definitively boring, time and money consuming and, helas, not performant enough (no correlation). Depending on your infrastructure, your devices can generate up to GigaBytes of log entries per day. It becomes impossible to review them manually. You need tools to achieve this.
On a security point of view, we don’t need to look for events (“something that happens at a time”) but incidents (“something that should NOT happen”). An incident is an adverse event. Thousands of events occur at a time, we need to focus on incidents! Events are collected, processed (filtered, normalized, aggregated) and archived. Incidents are results of correlations rules applied on events. Alerts can be triggered on specific incidents. Later, events can be processed for reporting purpose.
 |
There are commercial products which offer complete toolboxes to perform log analyzis. They are known as SIEM (“Security Information and Event Management”) or STRM (“Security Threat Response Management”). In July 2007, I already talked about SIEM in a previous article. Personally, I’ve experience with the following products:
Unfortunately, those solutions are very expensive and complex to deploy (not on a pure technical point of view but as a full project). Does it mean that correlation will never be available to small infrastructures? Certainly not! Event smallest infrastructure must be under control: “Know your network!”. One more time, the open source world provides us very nice tools.
| Let’s have a look at the schema on the right (Click to enlarge). To process the data, we need to perform the following steps: | 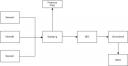 |
- Log centralization
- Backup logs: save two copies: one for immediate processing and one for forensics
- Data processing (cleanup, events correlation)
- Notifications if required
To achieve those steps, we will use the following piece of software:
|
Note: Only syslog messages will be covered here. Of course, for a complete monitoring, it will be mandatory to take into account all messages generated by the devices (SNMP traps are another good example). |
I’ll not explain how to install or configure the tools covered here. Only the interaction between then is important. Refer to their respective websites. Google will also be your best friend!
Log centralization
Why do we need to centralize all the logs? For easier management (further steps) but also to prevent data loss not only in case of hardware failure or human error but also security incident. If a server is compromised, the hacker will delete all the logs to remove all evidences. With a remote copy, you keep traces! Evidences must always be handled carefully (or they will loose their value as evidence). That’s why we need to create a copy of all logs as soon as possible and never process them (to avoid alteration of timestamps or data). Create another copy which will be processed by the event correlator.
syslog-ng is the best syslog server to achieve this. There are plenty of configuration examples on the Internet.
Correlation and Sanitization
Once we are ready to process messages, we will process the data via SEC. This Perl script performs the following actions:
- Suppress unwanted messages
- Match single message and take action(s)
- Pair events and take action(s)
- Match events against a threshold within a defined time period and take actions
There exists a SEC rulesets repository. It’s a good starting point to write yours.
Notification
As said in a previous post, I’m a real Groundwork addict. That’s why I use this one as reporting and alerting system. How? We will use the Nagios passive checks (Groundwork uses Nagios as back end.
Out-of-the-box Solutions
Personally, I like the integration of different tools. Each separate component can be fine tuned or adapted to exactly match your requirement. But, others would like to use something ready-to-use (even if we cannot use this term here, correlation will always require a lot of time to reach a good level of correlation).
Splunk is a nice tool which collects data and index them. It can be compared as a “Google” for logs. It provides several modules: Availability, Security, Compliance and Business Intelligence.
OSSIM is an Open Source Security Information Management. The name says enough. It’s more focussed on network security.
A Project
If you decide to implement log correlation, you’ll start a huge project. The required software components installation is straight forward but the analyze of your assets (inventory, vulnerability, availability, criticity), the sizing and design of correlation rules will be the hidden part of the iceberg. Don’t start with a too large scope, focus on major assets/events first.